Many beginners start learning ethical hacking with excitement. They install security tools, watch tutorials, create accounts on learning platforms and imagine themselves finding vulnerabilities like professional security researchers.
But after a few weeks, reality often feels different. Suddenly there are hundreds of concepts:
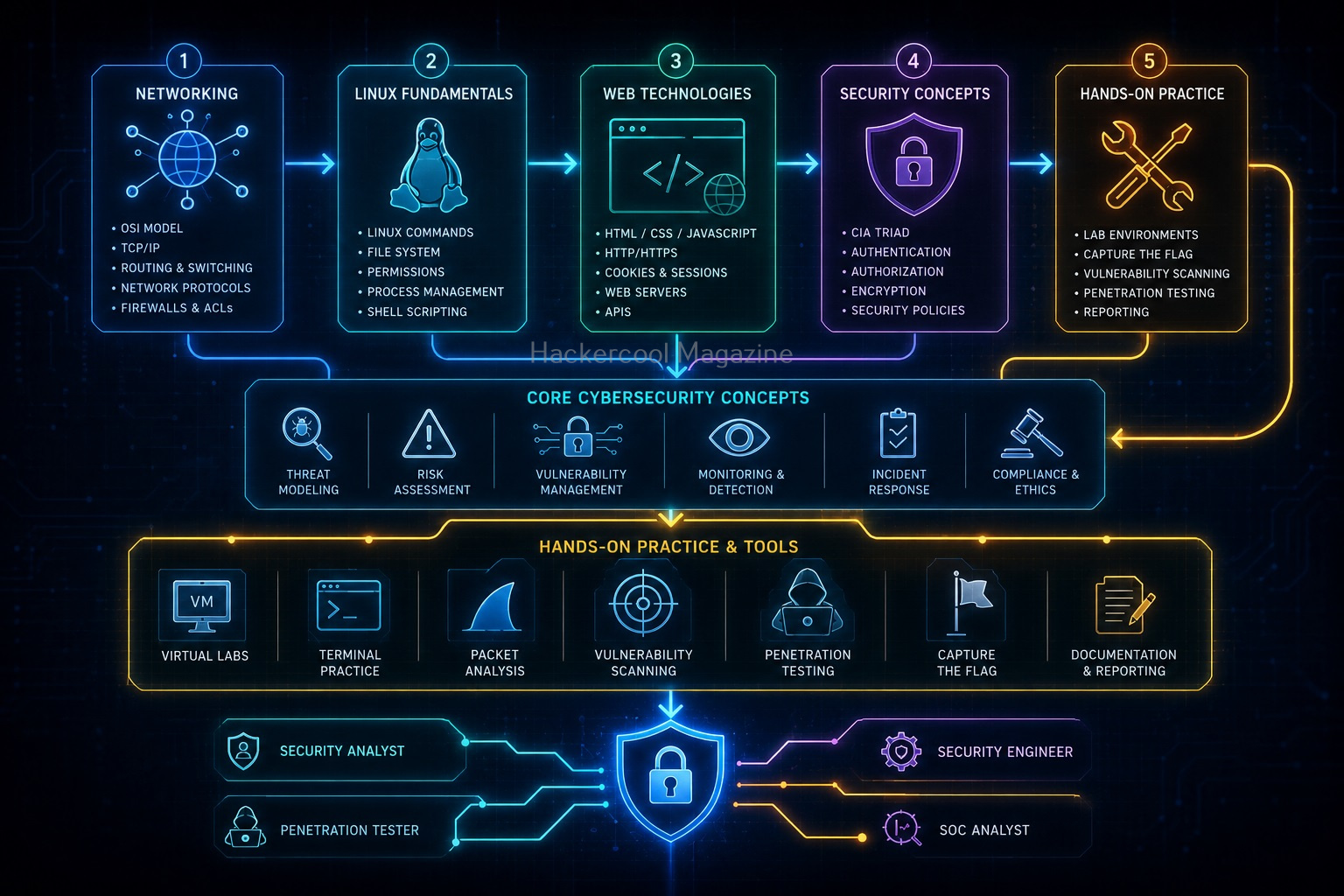
- Networking
- Linux commands
- Web applications
- Programming
- Security tools
- Vulnerabilities
- Operating systems
- Protocols
What looked exciting from the outside begins to feel confusing. Many beginners ask themselves.
“Why is ethical hacking so difficult?”
The answer is simple:
Ethical hacking feels difficult because you’re not learning one skill—you are learning how many different technologies work together. The challenge is real, but it becomes much easier when you approach learning the right way. In this guide, we’ll explore why ethical hacking feels overwhelming at first and how beginners can overcome those challenges.

Ethical Hacking Is Not Just “Hacking”
One of the biggest misunderstandings beginners have is thinking ethical hacking is only about running tools and finding vulnerabilities. Movies and online content often make hacking look instant.
Someone types a few commands. A few seconds later, access granted. Reality is completely different. Professional ethical hackers spend most of their time:
- Understanding systems
- Researching technologies
- Gathering information
- Testing carefully
- Documenting findings
The actual testing phase is only one part of the process. Before you can find weaknesses, you first need to understand how things work. Now, let’s look at the exact reasons why ethical hacking feels difficult.

Reason 1: There Are Too Many Things to Learn
The first challenge beginners face is information overload. When you enter cybersecurity, you quickly discover that it is a vast domain of:
- Network security
- Web security
- Cloud security
- Digital forensics
- Malware analysis
- Reverse engineering
- Threat hunting
Each topic contains even more subtopics. This creates the feeling that you’ll never learn enough.

How to Fix It: Follow a Learning Path
Don’t try to learn everything at once. Start with foundations.
Step 1: Networking Basics
Learn:
- IP addresses
- DNS
- Ports
- TCP/IP
- HTTP
Networking explains how computers communicate.
Step 2: Operating systems
Focus on:
- Linux basics
- Windows concepts
- File systems
- Permissions
You need to understand systems before securing them.
Step 3: Web Technologies
Learn:
- Websites
- Browsers
- Servers
- Databases
Many security concepts become easier once you understand web fundamentals.
Build layer by layer.

Reason 2: Beginners Skip the Basics
Many learners want to immediately start with advanced hacking techniques.
They skip topics like:
- Networking
- Linux
- Programming basics
- System administration
Because fundamentals don’t always feel exciting. This creates problems later.
Why Fundamentals Matter:
Imagine trying to solve advanced mathematics without knowing basic arithmetic. That’s what ethical hacking feels like without foundations. For example, a beginner may run a network scanning tool.
The tool shows:
- IP addresses
- Ports
- Services
- Protocols
But without networking knowledge, those results are confusing. The tool provides information but understanding creates skill.
How to Fix It: Learn How Things Work
Before asking:
“How do I hack this?”
Ask yourself:
“How does this work?”
Great security professionals are curious about technology.
Learn:
- How websites process requests
- How networks send data
- How operating systems manage users
- How applications store information
Understanding creates confidence.

Reason 3: Tools Feel Complicated
Cybersecurity has many tools. Beginners encounter:
- Scanners
- Testing frameworks
- Analysis platforms
- Monitoring tools
At first, these tools can seem intimidating. There are many options, commands and outputs.

How to Fix It: Learn Concepts Before Tools
A tool is just a helper. It automates a process.
Instead of memorizing buttons or commands, learn:
- What problem does this tool solve?
- What information does it collect?
- Why does this information matter?
Tools change. Concepts remain.

Reason 4: Tutorials Make Everything Look Easy
Online tutorials can create unrealistic expectations.
A tutorial often shows:
- A prepared environment
- Perfect steps
- Successful results
Everything works smoothly but real learning is different.
The Reality of Learning
You’ll experience:
- Errors
- Failed attempts
- Confusing results
- Problems to troubleshoot
This is normal. Troubleshooting is actually one of the most valuable skills you develop.

How to Fix It: Practice More
Don’t only watch tutorials.
After learning something:
- Try it yourself
- Experiment safely
- Take notes
- Understand mistakes
Hands-on practice turns information into skill.

Reason 5: Beginners Compare Themselves to Experts
This is a common problem.
You see experienced cybersecurity professionals:
- Finding vulnerabilities
- Creating tools
- Explaining advanced topics
And you feel behind. But you’re comparing your beginning to someone’s years of experience.

How to Fix It: Measure Your Own Progress
A better question is:
“Do I understand more than I did last month?”
Progress matters more than speed.
Every professional started by learning:
- Basic commands
- Simple concepts
- Beginner topics
Expertise develops over time.
Reason 6: Cybersecurity Requires Problem Solving
Unlike some subjects where you memorize answers, cybersecurity requires investigation.
You constantly ask:
- Why did this happen?
- How does this system work?
- What does this result mean?
This can feel difficult at first.
How to Fix It: Develop an Investigator Mindset
Think like a detective. Don’t rush.
Learn to:
- Observe details
- Research problems
- Test ideas
- Analyze results
Curiosity is one of the most valuable cybersecurity skills.
Reason 7: Progress Is Hard to Notice
When learning cybersecurity, improvement happens slowly. You might not notice daily changes but after months of practice, concepts that once seemed impossible become familiar.
How to Fix It: Document Your Learning
Keep notes about:
- Concepts learned
- Problems solved
- Tools explored
- Mistakes fixed
Documentation shows your progress. It also becomes your personal cybersecurity reference.
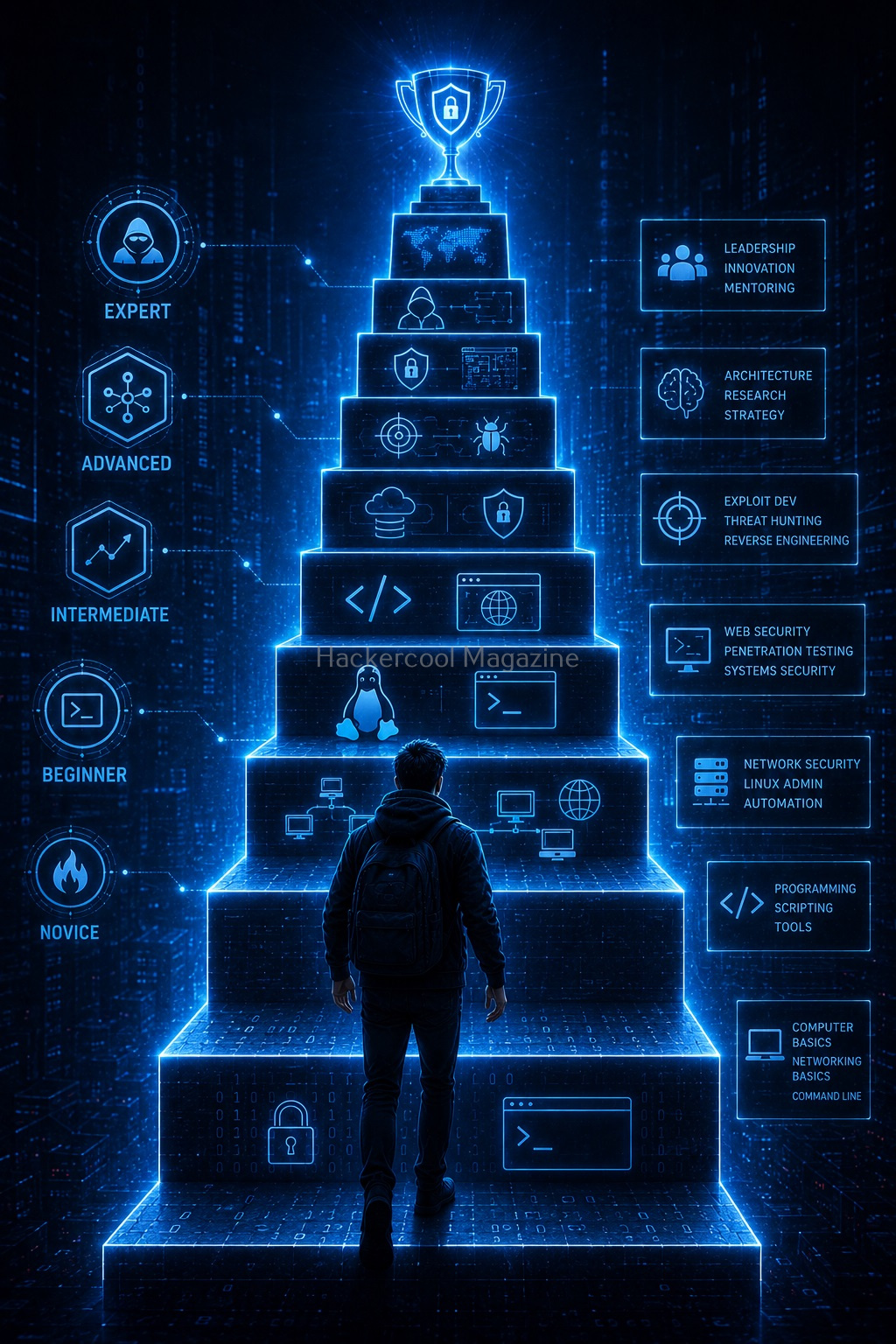
A Simple Beginner Learning Strategy
If ethical hacking feels difficult, follow the strategy given below to simplify your approach.
Month 1: Learn Networking
Understand how computers communicate.
Month 2: Learn Linux
Become comfortable using the command line.
Month 3: Learn Web Basics
Understand how websites and applications work.
Month 4: Learn Security Concepts
Study common vulnerabilities and defenses.
Month 5+: Practice
Build labs and apply knowledge.
Skills That Make Ethical Hacking Easier
To make learning ethical hacking easier, focus on building the following skills:
Patience:
Complex topics take time.
Curiosity:
Always ask how and why.
Consistency:
Small daily progress adds up.
Research Ability:
Learning how to find answers is essential.
Documentation:
Writing improves understanding.

What Beginners Should Remember
Ethical hacking feels difficult because:
You are learning how technology works at a deeper level.
That difficulty is part of the process.
Every confusing topic becomes easier with:
- Time
- Practice
- Repetition
- Experience

Conclusion
Feeling overwhelmed when starting ethical hacking is common. There are many technologies, concepts and skills to understand. But the solution is not learning faster. The solution is learning smarter.
Remember:
✔ Build strong fundamentals first
✔ Focus on concepts before tools
✔ Practice regularly
✔ Avoid comparing yourself to experts
✔ Document your journey
✔ Learn one step at a time
Ethical hacking becomes easier when you stop trying to memorize everything and start understanding how technology works. Stay curious, keep practicing and continue improving one concept at a time.